Network Overview
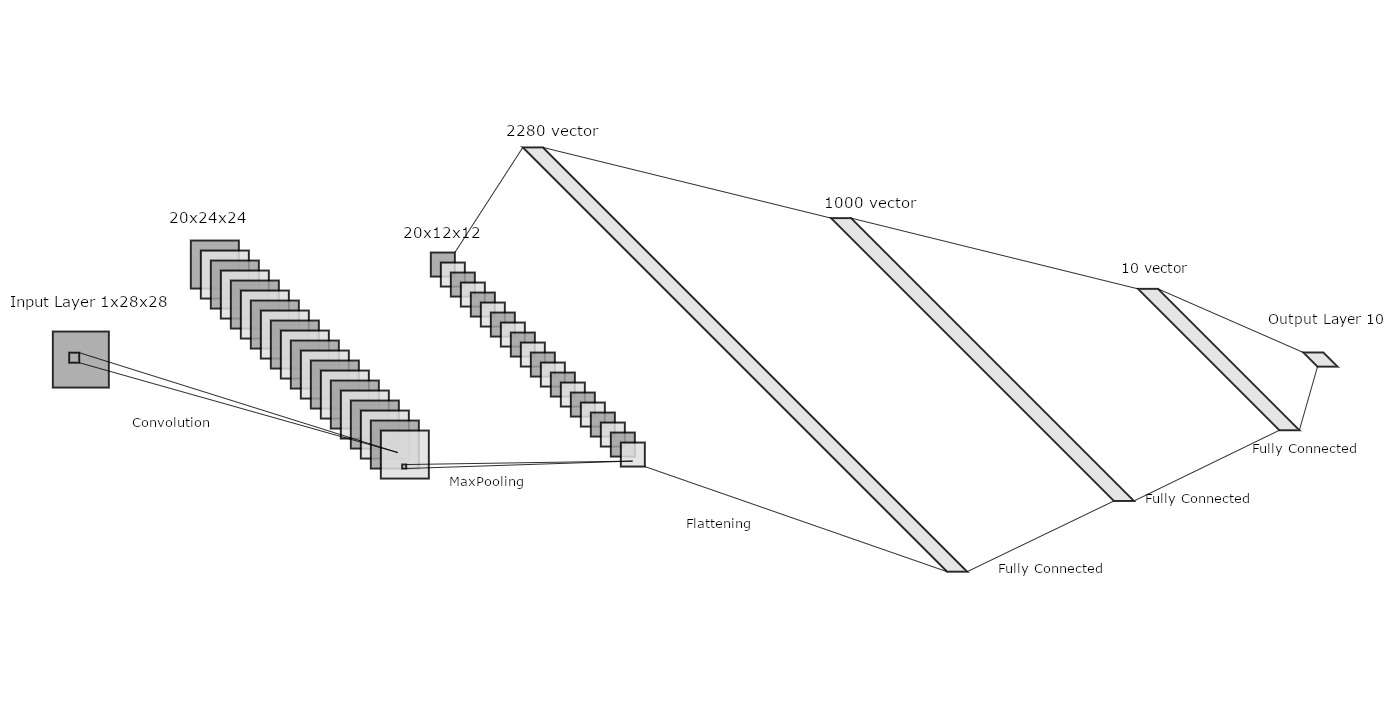
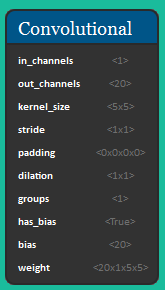
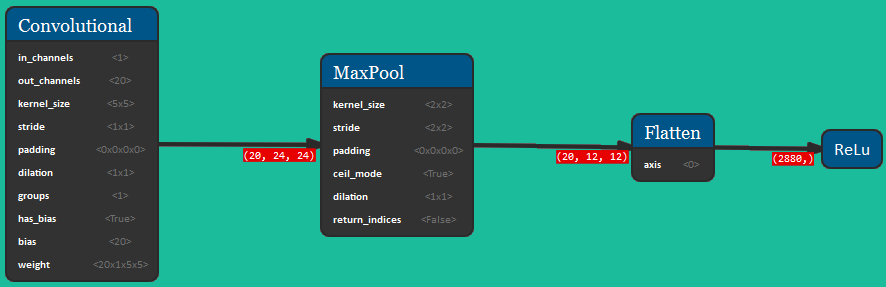
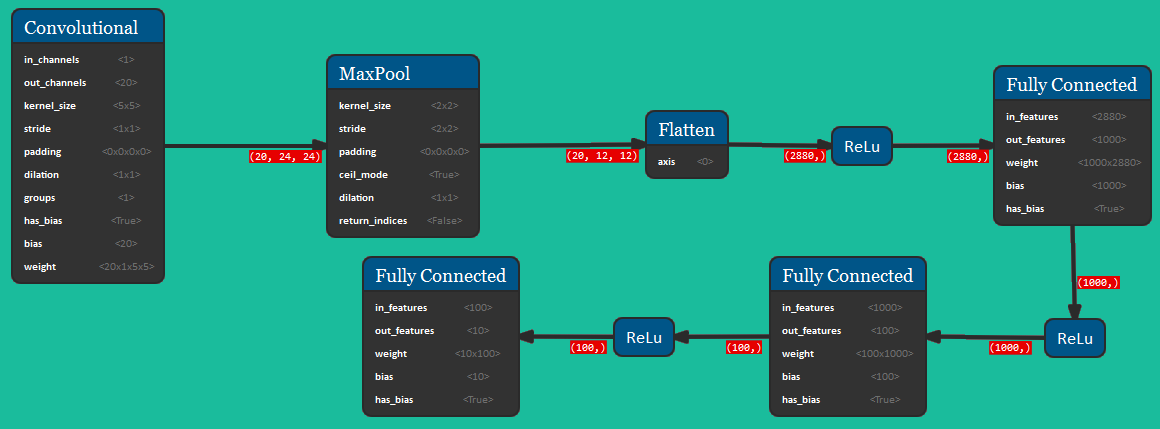
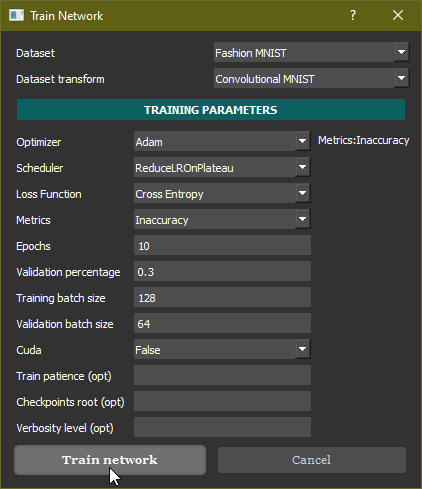
The picture below shows the formal representation of the Convolutional Neural Network for this dataset. The architecture consists of a convolutional block, followed by a MaxPooling and a Flattening operation; then there are 3 Fully Connected layers with ReLU activation functions. This network takes as input a 1x28x28 tensor and outputs a 1D vector of 10 elements.